CONVOL
The CONVOL function convolves an array with a kernel, and returns the result. Convolution is a general process that can be used for various types of smoothing, signal processing, shifting, differentiation, edge detection, etc. The CENTER keyword controls the alignment of the kernel with the array and the ordering of the kernel elements. If CENTER is explicitly set to 0, convolution is performed in the strict mathematical sense; otherwise, the kernel is centered over each data point.
Example

This example uses a kernel to detect diagonal lines in an image.
; Sample image
array = FIX(READ_PNG(FILEPATH('mineral.png', $
SUBDIRECTORY=['examples','data'])))
; Edge detection kernel
kernel = [ [0,1,0],[-1,0,1],[0,-1,0] ]
result = CONVOL(array, kernel)
im1 = IMAGE(array, LAYOUT=[2,1,1], RGB_TABLE=39)
im2 = IMAGE(result, LAYOUT=[2,1,2], /CURRENT)
Additional Examples
See Additional Examples for more code examples using the CONVOL function.
Using CONVOL
Assume R = CONVOL(A, K, S), where A is an n-element vector, K is an k-element vector (k≤n), and S is the scale factor. If the CENTER keyword is omitted or set to 1:
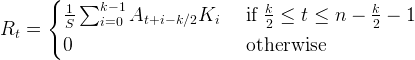
where the value k/2 is determined by integer division. This means that the result of the division is the largest integer value less than or equal to the fractional number.
If CENTER is explicitly set to 0:
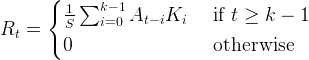
In the two-dimensional, zero CENTER case where A is an m-by-n-element array, and K is the k-by-k element kernel; the result R is an m by n-element array:
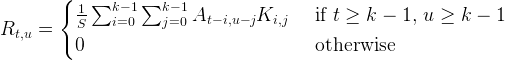
The centered case is similar, except the t-i and u-j subscripts are replaced by t+i-k/2 and u+j-k/2.
Syntax
Result = CONVOL( Array, Kernel [, Scale_Factor], BIAS=value, /CENTER, EDGE_CONSTANT=value, /EDGE_MIRROR, /EDGE_REFLECT, /EDGE_TRUNCATE, /EDGE_WRAP, /EDGE_ZERO, INVALID=value, MISSING=value, /NAN, /NORMALIZE )
Return Value
Returns the result of the array convolution. Depending on Array’s type, the computation might be performed using a different type, although the result will always have the same type as Array. The following table shows the types used, as well as any clipping of the result values. The calculation type is also used for Kernel, Scale_Factor, and BIAS.
|
Array Type |
Kernal and Calculation Type |
Clipping |
|
BYTE |
LONG |
[0,255] |
|
INT |
LONG |
[-32768,32767] |
|
LONG |
LONG |
None |
|
FLOAT |
FLOAT |
None |
|
DOUBLE |
DOUBLE |
None |
|
COMPLEX |
COMPLEX |
None |
|
DCOMPLEX |
DCOMPLEX |
None |
|
UINT |
LONG |
[0,65535] |
|
ULONG |
LONG |
None |
|
LONG64 |
LONG64 |
None |
|
ULONG64 |
LONG64 |
None |
Arguments
Array
An array of any basic type except string. The result of CONVOL has the same type and dimensions as Array.
Kernel
An array of any type except string. If the type of Kernel is not the same as Array, a copy of Kernel is made and converted to the appropriate type before use (for byte data, the kernel is converted to type LONG). The size of the kernel dimensions must be less than or equal to those of Array. CONVOL accepts non-square kernels including one-dimensional kernels.
Note: According to the mathematical definition of convolution, the kernel should be reversed before performing the computation. Since IDL does not reverse the kernel, it is actually computing the correlation rather than the convolution. For symmetric kernels this distinction is irrelevant. For asymmetric kernels, use REVERSE to change the order of the kernel argument to produce the convolution.
Scale_Factor
A scale factor that is divided into each resulting value. This argument should be of the same type as the input calculation, and will be automatically converted if necessary. For byte or integer input arrays, the argument allows the use of fractional kernel values and avoids overflow of the result. If omitted or set to zero, a scale factor of 1 is used.
Note: The same Scale_Factor is always divided into each result value, regardless of any missing data as specified by the INVALID or NAN keywords. It is usually not appropriate to divide the result value by the full scale factor if portions of the kernel were not applied due to missing data. In this case, you might want to use the NORMALIZE keyword instead.
Keywords
BIAS
Set this keyword to the bias offset to be added to each result value, after any Scale_Factor has been applied. BIAS should be of the same type as the calculation type, and will be automatically converted if necessary. If you have negative kernel values and a byte or unsigned integer input array, you can use this keyword to ensure that the result values are within the range of your data type.
Note: The same BIAS is always added to each result value, regardless of any missing data as specified by the INVALID or NAN keywords. It is usually not appropriate to add the full BIAS if portions of the kernel were not applied due to missing data. In this case, you might want to use the NORMALIZE keyword instead.
CENTER
Set or omit this keyword to center the kernel over each array point. If CENTER is explicitly set to zero, the CONVOL function works in the conventional mathematical sense. In many signal and image processing applications, it is useful to center a symmetric kernel over the data, thereby aligning the result with the original array.
Note that for the kernel to be centered, it must be symmetric about the point K(FLOOR(m/2)), where m is the number of elements in the kernel.
EDGE_CONSTANT
Set this keyword to a specific value to make CONVOL compute the values of elements at the edge of Array as if the array were padded by a constant value. For example, if the array values are represented by "abcdefg" then the effective array will be "...CCCC|abcdefg|CCCC...", where C is the EDGE_CONSTANT value.
Note: Unlike the other EDGE_* keywords (which are simple on/off keywords), EDGE_CONSTANT should be of the same type as the calculation type, and will be automatically converted if necessary.
Note: If none of the EDGE_* keywords are set, CONVOL sets the values of Result to zero (or the value of BIAS) where the kernel extends beyond the edge.
EDGE_MIRROR
Set this keyword to make CONVOL compute the values of elements at the edge of Array by “mirroring” the subscripts of Array at the edge. For example, if the array values are represented by "abcdefg" then the effective array will be "gfedcba|abcdefg|gfedcba".
If none of the EDGE_* keywords are set, CONVOL sets the values of Result to zero (or the value of BIAS) where the kernel extends beyond the edge.
EDGE_REFLECT
Set this keyword to make CONVOL compute the values of elements at the edge of Array by “reflecting” the subscripts of Array at the edge. This is similar to EDGE_MIRROR except the point at the very edge is not repeated. For example, if the array values are represented by "abcdefg" then the effective array will be "gfedcb|abcdefg|fedcba".
If none of the EDGE_* keywords are set, CONVOL sets the values of Result to zero (or the value of BIAS) where the kernel extends beyond the edge.
EDGE_TRUNCATE
Set this keyword to make CONVOL compute the values of elements at the edge of Array by repeating the subscripts of Array at the edge. For example, if the array values are represented by "abcdefg" then the effective array will be "...aaaa|abcdefg|gggg...".
If none of the EDGE_* keywords are set, CONVOL sets the values of Result to zero (or the value of BIAS) where the kernel extends beyond the edge.
EDGE_WRAP
Set this keyword to make CONVOL compute the values of elements at the edge of Array by “wrapping” the subscripts of Array at the edge. For example, if the array values are represented by "abcdefg" then the effective array will be "abcdefg|abcdefg|abcdefg".
If none of the EDGE_* keywords are set, CONVOL sets the values of Result to zero (or the value of BIAS) where the kernel extends beyond the edge.
EDGE_ZERO
Set this keyword to make CONVOL compute the values of elements at the edge of Array as if the array were padded with zeroes. For example, if the array values are represented by "abcdefg" then the effective array will be "...0000|abcdefg|0000...".
If none of the EDGE_* keywords are set, CONVOL sets the values of Result to zero (or the value of BIAS) where the kernel extends beyond the edge.
INVALID
Set this keyword to a scalar value of the same type as Array that should be used to indicate invalid data within Array. When computing the convolution for a particular point, any invalid values in the kernel's span will not be included within the sum. If all points within the kernel's span are invalid, the result at that point is given by the value of the MISSING keyword. See below for examples using the INVALID keyword.
Tip: The use of the INVALID keyword is equivalent to treating those values as 0.0 when computing the convolution sum. You can use the NORMALIZE keyword to exclude these points entirely.
Tip: For floating-point data, you can use the INVALID and NAN keywords simultaneously to filter out both user-defined values and NaN or Infinity values.
Note: The INVALID keyword uses a simple comparison to ignore values and should not be set to NaN. If you do have NaN's in your input, use the NAN keyword.
MISSING
Set this keyword to the value to return for elements in the Result where all of the points within the kernel's span were invalid. The default is zero for byte or integer input, and NaN for floating-point input. This keyword is only used if the INVALID or NAN keyword is set. See the bottom for examples using the MISSING keyword.
NAN
Set this keyword to cause the routine to check for NaN or Infinity values in the input data, and treat these values as invalid. When computing the convolution for a particular point, any invalid values in the kernel's span will not be included within the sum. If all points within the kernel's span are invalid, the result at that point is given by the value of the MISSING keyword. See the bottom for examples using the NAN keyword.
Tip: The use of the NAN keyword is equivalent to treating those values as 0.0 when computing the convolution sum. You can use the NORMALIZE keyword to exclude these points entirely.
Tip: For floating-point data, you can use the INVALID and NAN keywords simultaneously to filter out both user-defined values and NaN or Infinity values.
Note: You should always use the NAN keyword if the input array may possibly contain NaN or Infinity values. Note, however, that searching for these values will slow down the algorithm.
NORMALIZE
Set this keyword to automatically compute a scale factor and bias and apply them to the result values. If this keyword is set, the Scale_Factor argument and the BIAS keyword are ignored. For all input types, the scale factor is defined as the sum of the absolute values of Kernel. For BYTE or UINT, the bias is defined as the sum of the absolute values of the negative Kernel values, multiplied by either (255/Scale) for BYTE or (65535/Scale) for UINT, where Scale is the computed scale factor. For all other types, the bias is zero. See the bottom for examples using the NORMALIZE keyword.
Tip: If NORMALIZE is set and your input array has missing data (the INVALID or NAN keywords are set), then for each result value the scale factor and bias are computed using only those kernel values that contributed to that result value. This ensures that all result values are comparable in magnitude, regardless of any missing data. Use caution when analyzing these values, as the result may be biased by having fewer points within the kernel.
Thread Pool Keywords
This routine is written to make use of IDL’s thread pool, which can increase execution speed on systems with multiple CPUs. The values stored in the !CPU system variable control whether IDL uses the thread pool for a given computation. In addition, you can use the thread pool keywords TPOOL_MAX_ELTS, TPOOL_MIN_ELTS, and TPOOL_NOTHREAD to override the defaults established by !CPU for a single invocation of this routine. See Thread Pool Keywords for details.
Additional Examples
Smooth an Image with Missing Data
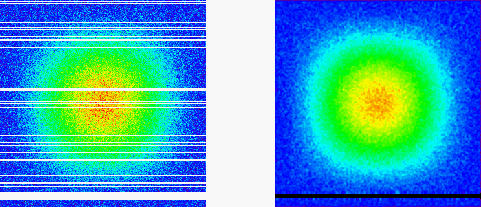
This example smooths a noisy image that has missing data and uses the NORMALIZE keyword to automatically remove much of the missing data.
; Array with noise
array = HANNING(300,300) + 0.1*RANDOMN(seed,300,300)
; Convert to bytes from [0, 254]
array = BYTSCL(array, TOP=254)
; Add some missing scanlines, plus a large region
; Use 255 as the missimg data value
array[*, RANDOMU(seed,40)*300] = 255
array[*, 10:20] = 255
; Simple 5x5 Gaussian kernel
kernel = GAUSSIAN_FUNCTION([1,1], WIDTH=5, MAXIMUM=255)
; Values of 255 are flagged as invalid (missing)
; and replaced by 0 if there are no valid values
; within the kernel
result = CONVOL(array, kernel, INVALID=255, MISSING=0, $
/EDGE_ZERO, /NORMALIZE)
i2 = IMAGE(array, LAYOUT = [2, 1, 1], RGB_TABLE=39)
i2 = IMAGE(result, LAYOUT = [2, 1, 2], RGB_TABLE=39, /CURRENT)
Smooth a Time Series with Missing Data

Here, we consider a time series with noise and missing data.
; Data with invalid values (marked as -999).
data = EXP(-[1:1.75:0.025]^2)
n = N_ELEMENTS(data)
data += 0.1*RANDOMU(1, n)
data[10:16] = -999
; Simple smoothing kernel
kernel = [1,2,4,2,1]/10.0
; Values of -999 are flagged as invalid (missing)
; and are not included in the convolution sum.
; Note: If we had NaN values in our array,
; then we would use NAN instead of INVALID.
smooth1 = CONVOL(data, kernel, INVALID=-999, /EDGE_ZERO)
; Use NORMALIZE to preserve "energy" near the gap
smooth2 = CONVOL(data, kernel, INVALID=-999, $
/EDGE_ZERO, /NORMALIZE)
; Plot our results. Use MIN_VALUE so we don't include
; the -999 invalid values.
p = PLOT(data, 'o-2', MIN_VALUE=-1, AXIS_STYLE=1, FONT_SIZE=9, $
XMINOR=2, YMINOR=2, /SYM_FILLED, DIM=[400, 300])
p.name = ' Original data'
p1 = PLOT(smooth1, 'or-2', /OVERPLOT, /SYM_FILLED)
p1.name = ' Convol with missing data'
p2 = PLOT(smooth2, 'ob-2', /OVERPLOT, /SYM_FILLED, SYM_SIZE=0.75)
p2.name = ' Convol with normalized kernel'
l = LEGEND(SHADOW=0,LINESTYLE='none', POSITION=[0.85, 0.9])
x = [0,1.5,1.5,7.5,7.5,18.5,18.5,n-2.5,n-2.5,n-1,n-1,0]
y = [0.5, 0.5, 0, 0, 0.5, 0.5, 0, 0, 0.5, 0.5, 0,0]
s = POLYGON(x, y, /DATA, FILL_COLOR='light gray', LINESTYLE='none')
s.Order, /SEND_TO_BACK
The gray regions indicate where the edges or the gap start to affect the returned values.
Notice that both smooth1 and smooth2 were able to fill in some of the INVALID values. However, once the kernel no longer covers any good points, then that value is treated as missing in the result. Notice also that for smooth1, on either side of the gap the smoothed values tend towards 0, as fewer good points are within the kernel. For smooth2, since we used the NORMALIZE keyword, the smoothed values retain their magnitude near the gap.
Version History
|
Original |
Introduced |
|
6.2 |
Added BIAS, EDGE_ZERO, INVALID, and NORMALIZE keywords |
|
8.1 |
Added EDGE_MIRROR keyword |
| 8.6.1 | Added EDGE_CONSTANT keyword |
| 8.9 | Added EDGE_REFLECT keyword |
See Also
BLK_CON, CONVOL_FFT, GAUSSIAN_FUNCTION, GAUSS_SMOOTH, LAPLACIAN, SAVGOL